チャートの形に「言語」は宿るか?ローソク足解釈 AI の挑戦
1. どんな論文?
この論文は、金融市場のローソク足データを予測するために特化して作られた、世界初の大規模オープンソース基盤モデル「Kronos」を提案しています。研究チームは、複雑な市場の動きをAIが理解できる階層的な「単語」へと翻訳する独自の手法を開発。 これにより、価格予測から投資シミュレーションまで、多様なタスクで既存の専門モデルを大幅に上回る性能を達成しました。設計が非常にユニークで、 AI の技術と金融の専門知識を融合させている点が高評価です。
2. チャートの形に「言語」は宿るか?金融市場特化AIの挑戦
私たち投資家は、株価チャートを読み解く際、ローソク足が作るパターン注目し、「これは上昇のサインかな?」「この形は危ないかも」といった予測を行います。さながらローソク足は何かしらの 市場の言語・暗号 のようです。
近年急速に発展している生成 AI は「言語の理解」が得意としていますが、こと「市場の言語」については、全く理解できないといって差し支えないでしょう。 金融市場のデータはノイズが多く、状況が刻一刻と変わるため、汎用的なAIモデルでは歯が立たないことが多かったのです。近年、ChatGPT のような強力な「基盤モデル」が登場しましたが、その学習データの大部分は一般的なテキストや画像であり、金融データはごくわずか。いわば、金融市場という特殊なドメインの「方言」を話せない状態でした。
今回紹介する論文は、この壁に正面から挑みます。著者らは、金融のローソク足データだけで学習させた、いわば「市場のネイティブスピーカー」と言える専門の基盤モデル「Kronos」を提案しています。
3. 論文の解説
この画期的な研究は、清華大学の Yu Shi 氏らによるものです。彼らは、なぜ既存のAIが金融市場で苦戦するのか、という問いから出発しました。
なぜ金融市場専用のモデルが必要だったのか?
研究者たちは、汎用的なAIモデルに金融データを少しだけ学習させても、市場特有の性質である
- 低い S/N 比 : ノイズに対する有用な情報の比率
- 非定常性 : 時々刻々と内部の状態が変化し、過去のモデルではうまく予測できないこと
は捉えきれない、と考えました。これは、あらゆる言語の辞書を少しずつかじった人が、専門的な議論のニュアンスを理解できないのに似ています。そこで彼らは、アプローチを根本から変え、金融データという一つの「言語」だけに集中して、その文法や語彙を徹底的に学ばせるモデルを構築することを目指したのです。
Kronosはどうやって市場の「言語」を学ぶのか?
Kronosの強さの秘密は、ローソク足の情報を「2段階で理解する」という独自の学習方法にあります。これは2つの主要なパーツで構成されています。
-
K-line Tokenizer (市場の通訳者): まず、連続的な数値データであるローソク足(始値・高値・安値・終値・出来高など)を、AIが扱いやすい離散的な「単語(トークン)」に変換します。ここでの独創的な点は、1つの単語を「粗い情報」を持つサブトークンと「細かい情報」を持つサブトークンの2つに分割することです。これは私たちがニュースを読むとき、まず見出しで概要を掴み(粗い情報)、次に本文で詳細を理解する(細かい情報)プロセスに似ています。
-
階層的自己回帰モデル (文章の執筆者): 次に、デコーダのみの Transformer モデルが、この「単語」の並びを学習します。予測を行う際も階層的で、まず過去の文脈から次の「見出し(粗いサブトークン)」を予測し、その見出しをヒントにして「本文(細かいサブトークン)」を予測します。この「粗から細へ」という手順を強制することで、モデルは市場の些細なノイズに惑わされることなく、本当に重要なパターンだけを安定して抽出できるようになります。
この「粗から細へ」という階層的な学習方法によって、AIは市場の些細なノイズに惑わされることなく、本当に重要なパターンだけを抽出できるようになったのです。
どのように性能を評価したか?
研究チームは、その性能を証明するために大規模なデータセットを用意しました。 東京証券取引所を含む世界45以上の取引所から、株式、暗号資産、FXなど多様な資産クラスにわたる120億件以上のローソク足データを収集。 この膨大なデータで Kronos を事前学習させ、様々な金融タスクで既存のモデルと比較しました。
どんなことが分かったか?
実験結果は驚くべきものでした。
- 驚異的な予測精度: 価格系列予測タスクにおいて、Kronosは既存の主要な時系列基盤モデルを最大で93%も上回る性能を達成しました。
- 高い汎用性: 価格予測だけでなく、ボラティリティ予測、合成データ生成、投資シミュレーションといった全てのタスクで、25もの比較対象モデルを凌駕し、最高性能を記録しました。
- 投資シミュレーションでの有効性: 中国A株市場でのバックテストでは、Kronosの予測シグナルを用いた戦略が、年率化超過リターン20.84%という優れたパフォーマンスを達成しました。
- スケール則の確認: モデルのパラメータ数を増やす(small→base→large)と、性能が一貫して向上することも確認され、AIモデルは大きいほど賢くなるという「スケール則」が金融時系列データにも存在することを裏付けました。
これらの結果は、Kronosが金融市場の「言語」を深く理解し、それを未来予測に応用できることを強く示唆しています。
4. 思ったこと
この論文を読んで、非常に興奮すると同時に、いくつか考えさせられる点がありました。
-
「翻訳」の巧みさこそが本質: ローソク足というアナログな情報を、 AI が解釈可能な「単語」に変換する tokenizer (翻訳機)の設計が非常に巧みに感じました。時系列データの離散化自体は新しいアイデアではありませんが、今回の対象であるローソク足データを「粗→細」という階層構造に落とし込み、基盤モデルの文脈でスケールさせた点が画期的です。
-
AI が自発的にパターンを学習できる可能性: 従来のテクニカル分析では、専門家が考案したテクニカル指標やパターンを機械が検出し、予測に活用されていました。 ですが Kronos のように「市場データを直接読み解く」 AI モデルが発達すると、人間には到底処理できない規模のデータから、より確率の高いパターンを見つけ出してしまうかもしれません。今回の対象はローソク足のみですが、 AI の強みを最大限活かすならば、あらゆる種類のデータを与え、多大な時間をかけて学習させるべきでしょう。
-
バックテストの限界は常に意識したい: 論文で示された年率20%超のリターンは素晴らしいですが、これはあくまで取引コストやスリッページ(注文価格と約定価格のズレ)を単純化したシミュレーション上の話です。現実の市場で同じパフォーマンスを再現するのは容易ではありません。また、モデルのコンテキスト長(一度に考慮できる過去の期間)が512トークンに制限されているため、数年単位の超長期的なサイクルを捉えるのは苦手かもしれません。
-
オープンソース化の大きな意義: この強力なモデルがオープンソースとして公開されている点は、非常に重要です。これにより、世界中の研究者や個人投資家がモデルを追試し、改良し、新たな応用を探ることができます。金融AIの民主化を大きく前進させる一歩と言えるでしょう。
5. 検証してみました
論文の主張、特にその心臓部である「市場の言語化」というアイデアが本当に機能するのか。私も、このアプローチを軽量に再現し、日本株データで試してみました。
今回は Kronos の巨大な Transformer モデル全体を動かすのではなく、その前段にある「K-line Tokenizer」、つまりローソク足を「単語」に変換する部分のアルゴリズムを再現します。これにより、日本語の文章に文法があるように、日本市場のローソク足にも特有の「単語」や「方言」が存在するのかを探ります。
結果、ローソク足の形を離散的な「単語」に変換すること自体は可能で、銘柄ごとに特有の「方言」、つまり出やすいパターンやその後の値動きのクセがあることが見えてきました。ただ、短い文脈から次の単語を正確に予測するのは、そう簡単ではないようです。
ローソク足が「単語」に変わる様子
まず、日経平均のローソク足が、開発したトークナイザによってどのように「単語(トークンID)」に変換されるかを見てみましょう。学習プロセスなしに、各ローソク足の形や大きさ、位置関係に基づいて、決定論的にIDが割り振られていきます。
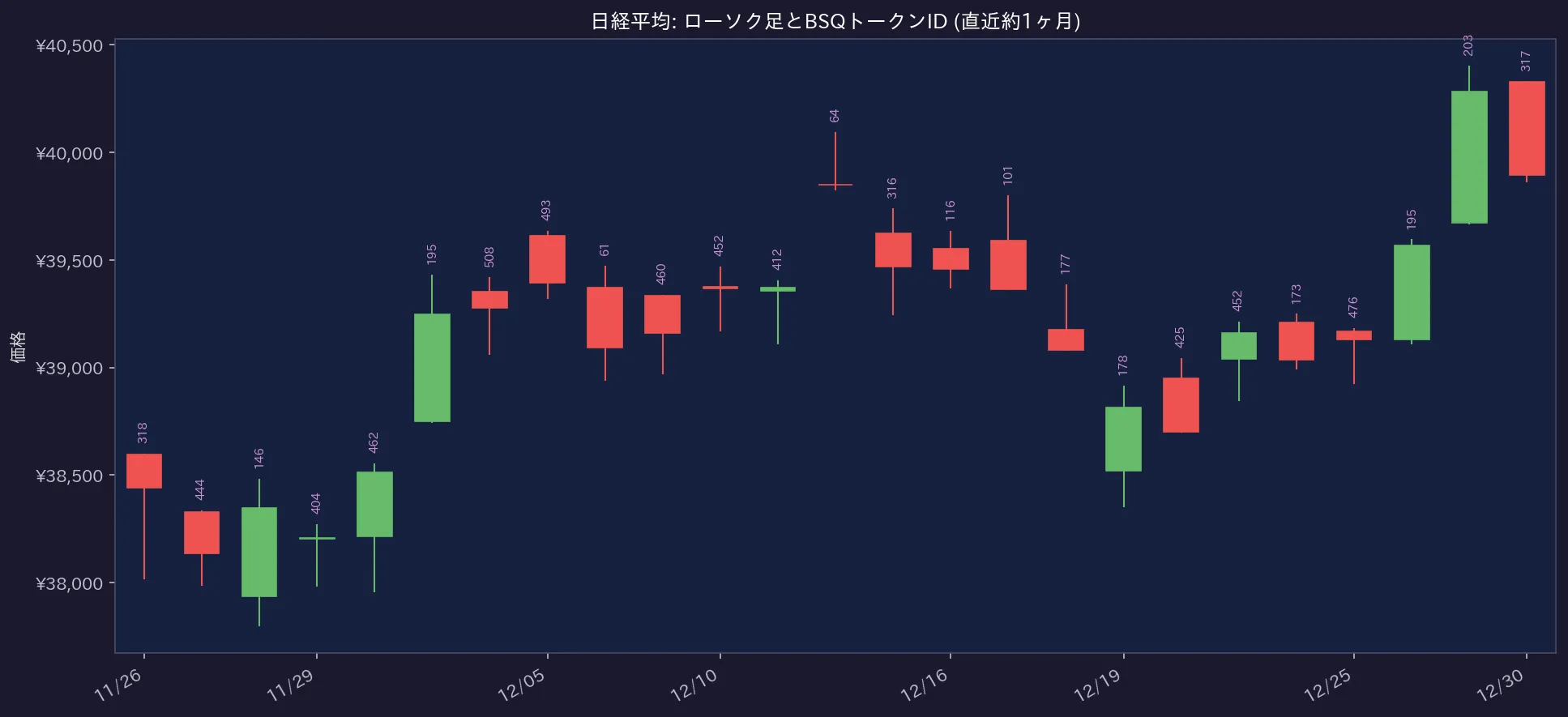 日経平均の直近約1ヶ月のローソク足と、各バーに対応するBSQトークンID。連続的な値動きが、機械的に離散的な「単語」に変換されている様子がわかります。
日経平均の直近約1ヶ月のローソク足と、各バーに対応するBSQトークンID。連続的な値動きが、機械的に離散的な「単語」に変換されている様子がわかります。
銘柄ごとの「方言」を探る
次に、この「単語」が銘柄ごとにどのような特徴を持つのか、つまり「方言」があるのかを調べました。ここでは代表として、TOPIX、トヨタ自動車(7203)、アドバンテスト(6857)の3銘柄について、頻繁に出現する「単語」や、その「単語」が現れた翌日の株価リターンが高かった/低かったものをまとめました。
| 銘柄 | 役割 | トークン | 方向 | 出現数 | 翌日リターン中央値 | K-lineパターン (推定) |
|---|---|---|---|---|---|---|
| TOPIX | 最頻トークン | 317 | 下降系 | 94 | +0.12% | 大陰線・上ヒゲ無・下ヒゲ中 |
| 高リターン | 286 | 下降系 | 5 | +0.62% | 陽線・上ヒゲ無・下ヒゲ長・高ボラ | |
| 低リターン | 179 | 下降系 | 9 | -0.95% | 大陽線・上ヒゲ中・下ヒゲ無・窓開け下 | |
| トヨタ自動車(7203) | 最頻トークン | 317 | 下降系 | 100 | +0.02% | 大陰線・上ヒゲ無・下ヒゲ中 |
| 高リターン | 445 | 下降系 | 5 | +1.18% | 大陰線・上ヒゲ無・下ヒゲ中・低ボラ | |
| 低リターン | 410 | 上昇系 | 5 | -1.81% | 大陽線・上ヒゲ無・下ヒゲ長・窓開け下 | |
| アドバンテスト(6857) | 最頻トークン | 317 | 下降系 | 95 | +0.53% | 大陰線・上ヒゲ無・下ヒゲ中 |
| 高リターン | 155 | 上昇系 | 7 | +3.32% | 大陽線・上ヒゲ無・下ヒゲ無・窓開け下・高ボラ | |
| 低リターン | 59 | 下降系 | 5 | -3.19% | 十字線・上ヒゲ長・下ヒゲ中・窓開け下・高ボラ・大商い |
面白いことに、TOPIX、トヨタ、アドバンテストの3銘柄すべてで、最も頻繁に出現した「単語」は同じID「317」でした。これは「大陰線で、上ヒゲがなく、下ヒゲが中くらい」のパターンに対応するようです。市場全体と個別株に共通する基本的な「語彙」が存在することを示唆しています。
一方で、「方言」も明確に見られます。特に高ボラティリティのアドバンテストでは、特定の「単語」が出現した後のリターンが極端に大きい(トークン155の翌日中央値 +3.32%)または小さい(トークン59の翌日中央値 -3.19%)傾向がありました。これは、銘柄の特性によって「単語」の持つ意味合いが大きく異なることを示しています。
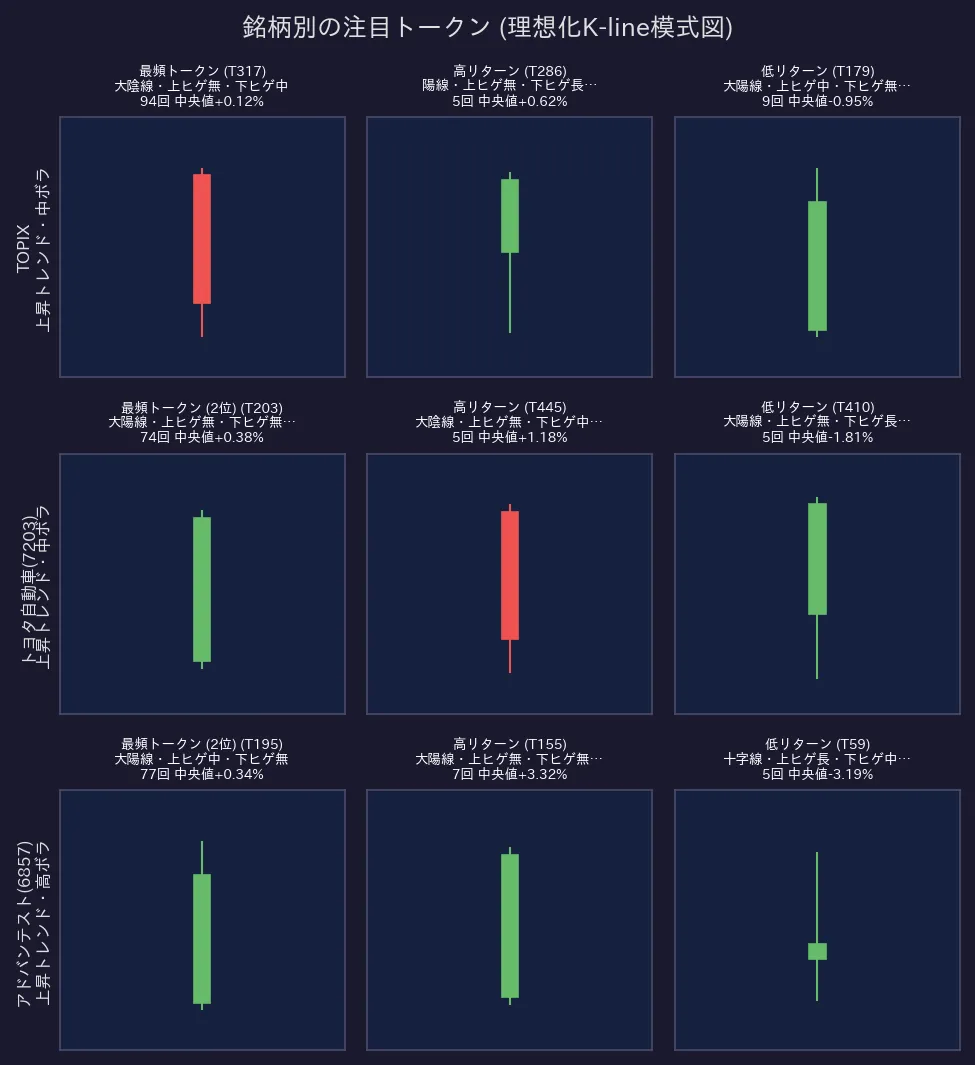 各銘柄の注目トークンが、どのようなローソク足の形に対応するかを可視化したもの。最頻出パターンは似ていますが、高リターン・低リターンにつながる特徴的なパターン(方言)は銘柄ごとに大きく異なることがわかります。
各銘柄の注目トークンが、どのようなローソク足の形に対応するかを可視化したもの。最頻出パターンは似ていますが、高リターン・低リターンにつながる特徴的なパターン(方言)は銘柄ごとに大きく異なることがわかります。
次の「単語」は予測できるか?
では、これらの「単語」の並びから、次に出現する単語を予測することはできるのでしょうか? 2つのシンプルなモデルで試してみました。
- 直前トークンから予測: 直前の1単語だけを見て次を予測するモデル。予測には Markov Chain を採用しました。
- 直近5トークンの文脈から予測: 直近5単語の並び(文脈)を見て次を予測するモデル。予測には LightGBM を用いました。
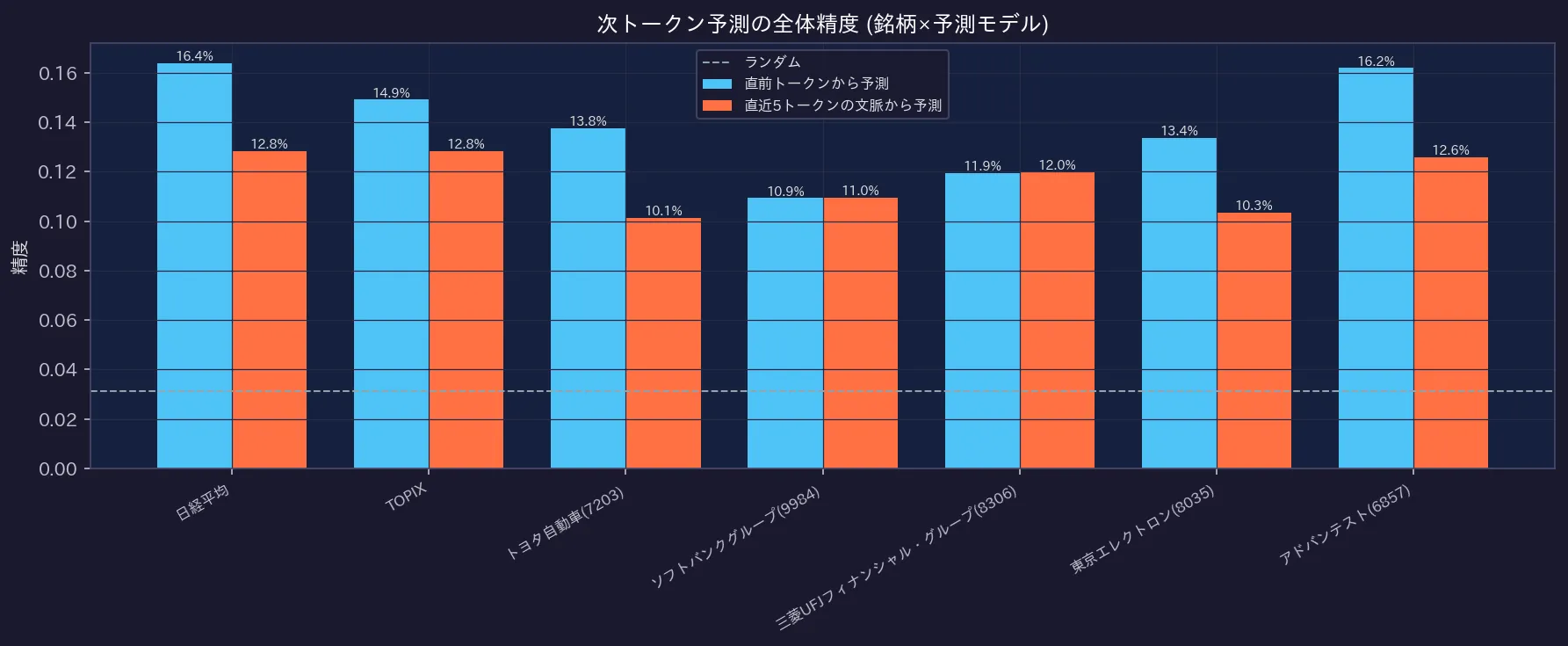 7銘柄すべてで、直前の1単語から予測するだけでも、ランダム(破線、3.12%)を大幅に上回る精度(10%〜16%)を達成しました。市場の動きが完全なランダムではないことを示しています。
7銘柄すべてで、直前の1単語から予測するだけでも、ランダム(破線、3.12%)を大幅に上回る精度(10%〜16%)を達成しました。市場の動きが完全なランダムではないことを示しています。
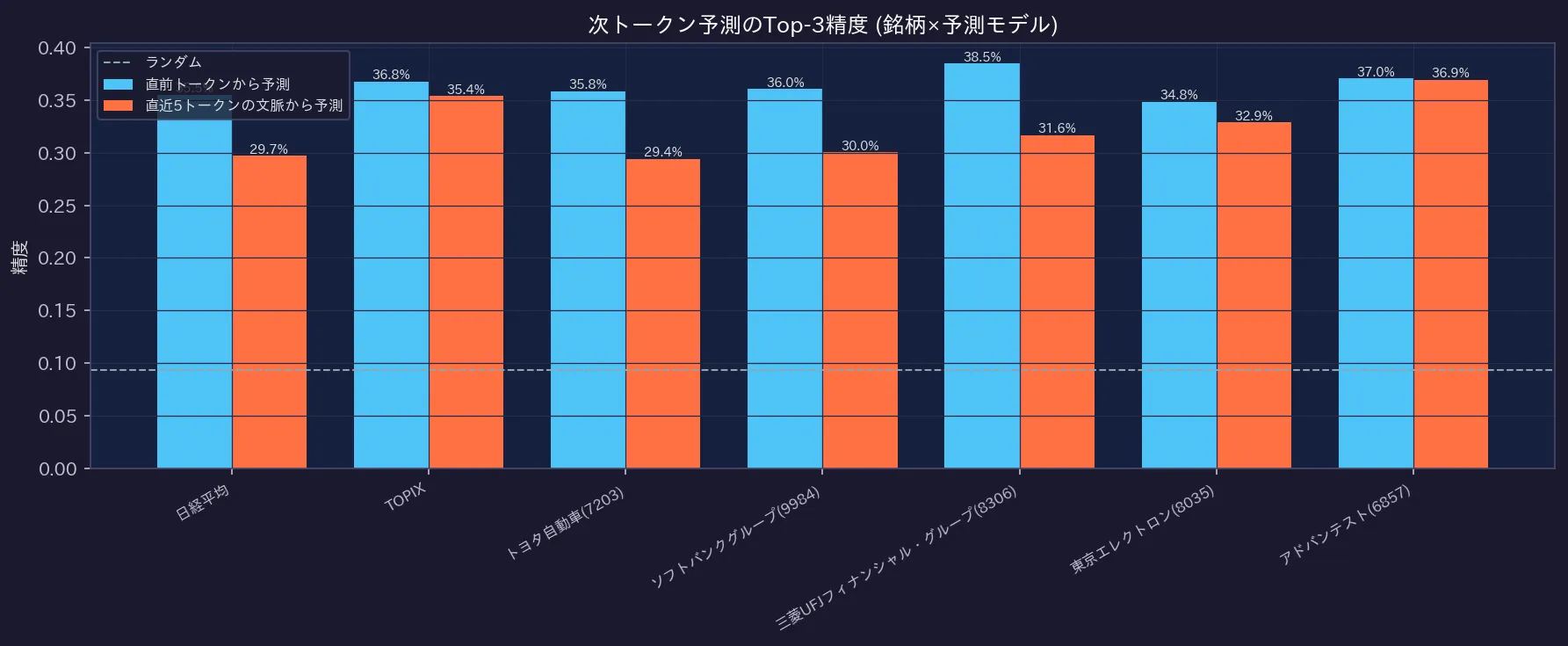 正解が予測確率上位3候補に含まれる確率(Top-3精度)でも、ランダム(破線、約9.4%)を大きく上回りました。
正解が予測確率上位3候補に含まれる確率(Top-3精度)でも、ランダム(破線、約9.4%)を大きく上回りました。
| 銘柄 | モデル | 全体精度 | Top-3精度 |
|---|---|---|---|
| 日経平均 | 直前トークンから予測 | 16.39% | 35.50% |
| 日経平均 | 直近5トークンの文脈から予測 | 12.84% | 29.68% |
| TOPIX | 直前トークンから予測 | 14.92% | 36.76% |
| TOPIX | 直近5トークンの文脈から予測 | 12.84% | 35.37% |
| トヨタ自動車(7203) | 直前トークンから予測 | 13.77% | 35.83% |
| トヨタ自動車(7203) | 直近5トークンの文脈から予測 | 10.14% | 29.41% |
| アドバンテスト(6857) | 直前トークンから予測 | 16.19% | 37.04% |
| アドバンテスト(6857) | 直近5トークンの文脈から予測 | 12.58% | 36.92% |
結果は興味深いものでした。直前のたった1つの「単語」から次の単語を予測するだけでも、精度はランダム(3.12%)を大幅に上回り、10〜16%に達しました。これは、市場の動きには確かにある程度の連続性やパターンが存在することを示しています。
一方で、より多くの情報(5単語の文脈)を与えたモデルの方が、多くの銘柄で精度が下がってしまいました。 これは、この軽量な検証設定および少数データでは、短い文脈から複雑なパターンを学習しきれなかったことを意味します。 この結果は逆説的に、単純なモデルでは捉えきれない、より長く複雑な「文法」を学習するために、 Kronosのような巨大な Transformer モデルがいかに重要であるかを浮き彫りにしています。
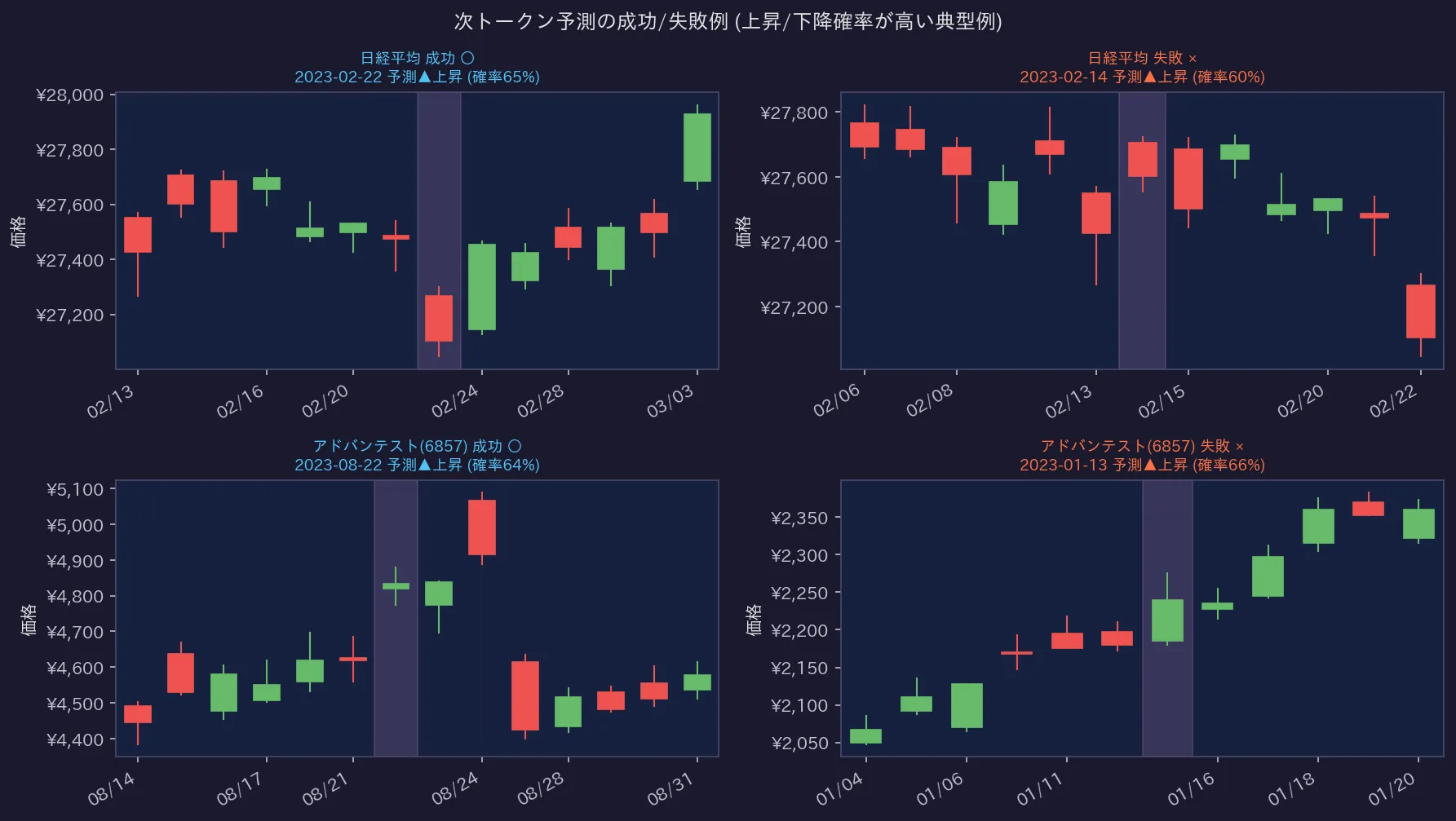 モデルが「次は上昇/下降しそうだ」と強く予測した日の例。予測通りに動く日もあれば、全く逆の動きをする日もあります。なかなか一筋縄ではいかないです。
モデルが「次は上昇/下降しそうだ」と強く予測した日の例。予測通りに動く日もあれば、全く逆の動きをする日もあります。なかなか一筋縄ではいかないです。
今回の検証は論文の軽量な再現であり、限界はありますが、市場の動きを「言語」として捉えるアプローチの面白さと、その解読の難しさの両面を垣間見ることができました。
6. まとめ
- やったこと: 金融市場のローソク足データを「言語」と見なして予測する、画期的な基盤モデル「Kronos」を紹介しました。さらに、その核心である「トークナイザ(単語化装置)」を軽量に再現し、日本株データに潜む「方言」を探りました。
- 分かったこと: ローソク足を「単語」に変換するアプローチは有効で、市場には共通の「語彙」と銘柄固有の「方言」が存在することが分かりました。しかし、次の一手を予測するには、Kronosのような巨大なAIモデルが持つ、複雑な「文法」を読み解く力が必要なようです。
- これから気になること: この研究は、AIによる市場分析のパラダイムシフトの始まりかもしれません。今後、AIが発見した「儲かる文法」が具体的に何を意味するのか、その解釈性が問われるでしょう。そして、誰もがこのAIを使うようになった未来の市場は、一体どうなってしまうのでしょうか。とても気になりますね。